原文链接:https://www.leiphone.com/news/201705/twh0WVrQ9sW9areZ.html
深度学习的需要
- 学习就是建立预测模型的过程。
- 深度学习的所有输入输出都可以用矩阵来表示。(线性代数)
- 概率来提供决策的依据。
深度:为何高效
多层神经网络。
学习:寻找关联f的过程
- x:问题描述。
- f:解题的方法。
- y:对应的答案。
- 难点:需要在未见过的任务上表现良好。
1 | graph LR |
关于f的寻找
能够拟合训练集的关联f并非唯一。
比如我想两个数字相加为1,我可以通过权重让一个数字为1,另一个为0,也可以一个是-299,另一个取300.
维度诅咒
维度越大,我们越无法获取所得的情况。
面临没有见过的情况,一般是左右的情况平均一下。但是这种方法在高纬度数据下并不适用。
Distributed Representation
这就引入了第一个自然界的先验知识:并行组合。也就是深度学习中分布式表达distributed representation的思想。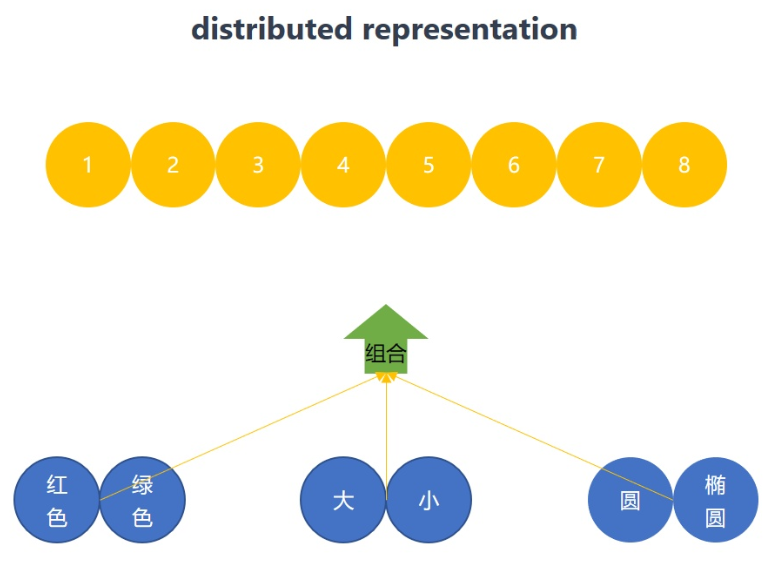
- 原本需要8个不同的情况,现在只需要6个,这8个变体又是3种因素组合而成的。
- 图中椭圆这个factor实际上也是有变体,可以以相同的思路继续拆分,继续降低训练所需要的数据量。
No Free Lunch Theorem(无免费午餐)
既然关联f是无限的,那么寻找关联f好比是大海捞针。不同的机器学习算法只是更擅长在某个海域打捞而已。如果重点打捞某个区域,那么其他的区域就会被忽略。所以如果想要打捞的关联f可以存在于大海的任何地方,那么深度学习并不会比其他的机器学习算法更优秀。这种情况下,任何两个机器学习算法都是等价的。
但是事实上并非如此,因为自然界中的很多任务,其关联f并非像我之前可以出现在大海当中的任何位置,而是会集中在特定海域,那些符合自然物理现象的特定海域。而深度学习就是擅长打捞该海域的机器学习算法。
深层vs浅层
第二条先验知识:那就是迭代变换。
我们知道原子会形成分子,而事物是在原子所形成的分子的基础上,进一步迭代形成的,并非再从原子开始重新生成。飞机是由原子到分子再到各式各样的零件组合形成的。坦克同样也利用到了相同的分子层。虽然作为图片,坦克和飞机是不同的样本,但是他们都共享着相同的分子层。这意味着当你用深层神经网络时,训练飞机样本会间接的对坦克进行了训练,降低了训练所需要的数据量。
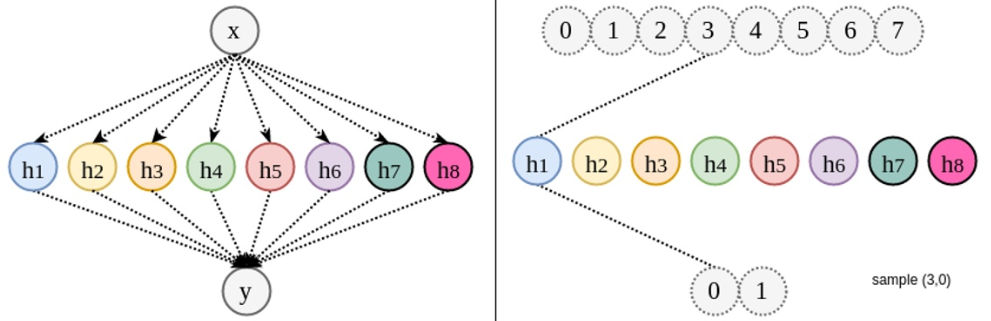
分布式表达(distributed Representation)将变体拆分成因素。但是如果无限节点的浅层网络,所拆分的变体并不会在不同的样本之间形成共享。
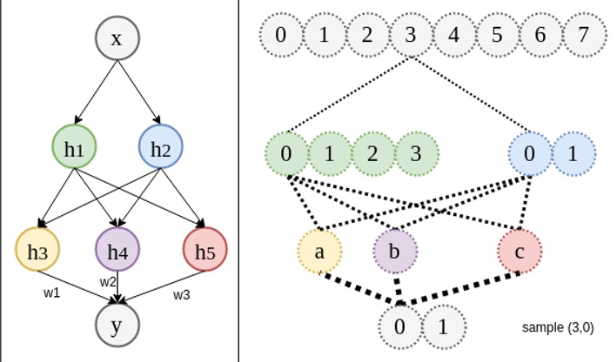
深层神经网络,由于拆分的变体可以在不同样本间共享,在浅层网络中只负责学习自己的关联,而在深层网络中,那些共用的相同因素的样本也会被间接训练到。深层的优势在于节省了训练所需要的数据量。
- 目前描述的网络叫做深层前馈神经网络,feedforward neural network。变换只会一层接着一层进行,不同层之间不会有跳跃,并且组合也是在同一层内的因素间进行的。
- 想象如果一个网络中的某个节点可以和其他的任何节点连接,那么这样的网络就没有任何的侧重。好比在你找人时被告知,他无处不在和他在哪都不在。这就相当于没有加入先验知识,没有缩小寻找关联f的海域。
所以前馈神经网络的这种连接方式,很好的缩小了训练所用的数据量。因为这种组合方式比较符合自然界的物理形成规律。
feedforward neural network 有两个先验知识,并行和迭代。有了这两个先验知识,缩小了f的范围,也就是缩小了假设空间。
假设空间(hypothesis space),指我们在那个范围内寻找关联f。并行:新状态是由若干旧状态并行组合形成。
- 迭代:新状态可由已形成的状态再次迭代形成。
前馈神经网络可以适用于几乎所有的任务,但它非常一般性,所提供的先验知识的针对性很低。
先验知识不够针对,那么训练所需要的数据量就会变大,并且过深之后会将那些噪音的形成规则也学习到模型当中,而这些规律并不是我们想要的。
而神经网络的其他变体,比如循环神经网络,卷积神经网络就提供了更多十分具有针对性的先验知识,可以缩小搜索的海域面积,排除掉那些噪音规律所带来的额外干扰。
不同的神经网络变体,就在于你向其中加入了不同的先验知识。
应用:设计理念
深层神经网络的优势就在于因素拆分,因素共享,设计神经网络基于这两点,前馈神经网络就是基于这两点的基本形式,但是神经网络并不仅限于这种形式。设计神经网络更像是玩乐高积木,但是玩的规则在于如何拆分因素,如何使不同的样本之间形成因素共享。所以在看到很多新的网络结构时,请务必考虑,他们的结构是如何考虑因素拆分和因素共享的。
时间共享 循环神经网络RNN
以陶瓷的塑形为例,用循环层做时序预测,相当于使用转盘,摆出一个手型后,每个角度都是以这种手型去捏制的。
空间共享 卷积神经网络CNN
作者提出的四个设计原则
设计神经网络实质上就是在对假设空间进行调整。也就是选择在哪些片海域寻找你的关联f。
增加共享,降低确定关联f所需要的数据量。如果你知道它大致在大海的哪个范围后,就可以使用更少的渔网,更快的打捞上来。
增加惩罚,我们可能会事先知道关联f不满足哪些特点。那么一旦这种特点的关联f在训练中被找到时,我们就对结果进行惩罚,起到筛选作用。用打鱼做比喻的话,那些不符合条件的小鱼会被大孔渔网筛选掉。
优化起点,我们优先从哪片海域先开始寻找,找不到再找其它的海域。
降低变体数,变体数量越多,我们就需要见到越多的数据。所以我们可以预处理数据,将变体数量在学习之前就降低下去。比如将数据减去平均值,除以均差。
应用以上原则的技术,从先验知识的角度
迁移学习
利用因素共享这一特点,将一个任务中学到的关联应用于其他的任务中去。
将已经训练好的,用于识别动物的神经网络的前几层这个f1拿出来,在识别植物的神经网络中,额外加两层再做轻微训练,同样适用,毕竟大家都是人眼,这部分的f1很大程度上是共享的。
这就是迁移学习。
1 | graph LR |
多任务学习
多任务学习其实和迁移学习使用的是相同的先验知识。多任务学习,是在训练的时候用共享着相同底层知识的其他任务的数据来帮助一起训练。可以起到扩充训练数据量的作用。同时寻找到的关联f更加优秀。因为三个不同的任务对底层的知识同时进行了约束。只有同时满足三个不同任务的关联f才会被采用,这就排除掉那些只符合单个任务的关联f。
跨层组合
这是另一条先验知识,我们知道前馈神经网络是不允许跨层组合的。残差网络就是拥有这种特点的神经网络。
比如说我们在判断一个人的时候,很多时候我们并不是观察它的全部,或者给你的图片本身就是残缺的。这时我们会靠单个五官,外加这个人的着装,再加他的身形来综合判断这个人。这样,即便图片本身是残缺的也可以很好的判断它是什么。这和前馈神经网络的先验知识不同,它允许不同层级之间的因素进行组合。
蒸馏模型
其本质仍然属于迁移学习,但是将知识以不同的方式迁移。一般的迁移学习是将学到的权重直接用在新的模型当中,迁移的是权重。而蒸馏模型所迁移的是标签。
有两个模型,完成的任务是相同的,但是叫做老师的这个模型拥有更好的特征(输入),而叫做学生的这个模型由于实际应用的约束,无法使用这样的特征。
蒸馏模型的做法是先训练老师模型,用老师模型的预测值作为一种额外的标签,在训练学生模型的时候和学生模型自己的标签一同使用,帮助学生模型寻找到更好的关联f。而这种帮助过程只发生在训练阶段,实际的使用中,只用学生模型。这就好比一个学生在做题的时候,他既有参考答案,又有一个家教的指导。虽然家教无法代替学生去考试。因为有家教的辅导,这个学生会比没有家教辅导的学生更容易学习。
自动编码器
自动编码器是利用并行与迭代的这两个先验知识,来操控变体的一种技术。用作生成模型和特征工程。
Batch normalization
一般我们会在输入和输出进行预处理,减去均值和标准差,降低变体数量。这个思路一样可以在隐藏层实施。因为输入和输出是事物的状态,有变体,隐藏层同样是发展的中间状态,也有变体。